Batch Processing: Thousands of AI Responses Efficiently
Process thousands of AI requests efficiently with NeuroLink's batch processing patterns. Concurrency control, error resilience, and throughput optimization for production workloads.

In this guide, you will process thousands of AI requests efficiently using NeuroLink’s batch processing patterns. You will implement concurrency-controlled batch execution, progress tracking, error recovery with checkpointing, and cost-optimized model selection for high-volume workloads.
The naive approach – processing items sequentially – is painfully slow. A batch of 1,000 items at 2 seconds per request takes over 30 minutes. But the opposite extreme – launching all 1,000 requests simultaneously – overwhelms rate limits and produces a cascade of 429 errors.
The solution is controlled concurrency: processing multiple requests in parallel while respecting provider rate limits and isolating errors so a single failure does not bring down the entire batch. NeuroLink’s architecture supports this through the maxConcurrency configuration in PerformanceConfig and the p-limit pattern used internally for operations like concurrent image generation.
In this tutorial, you will learn how to build batch processing pipelines that handle thousands of items efficiently, with retry logic, progress tracking, and structured output support.
Concurrency Architecture
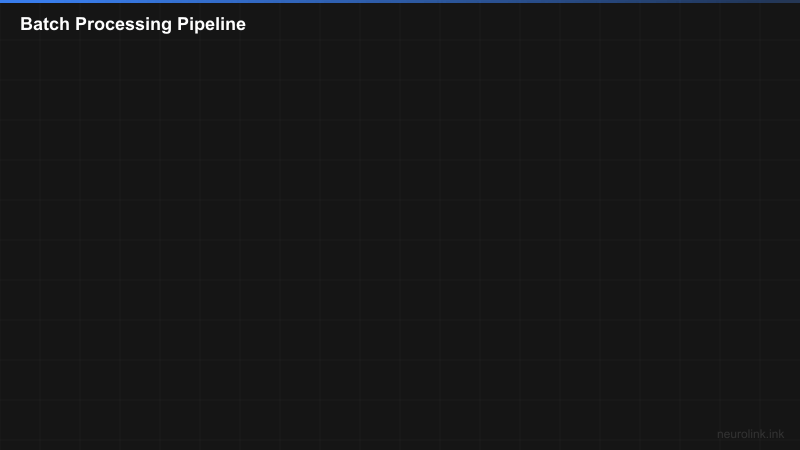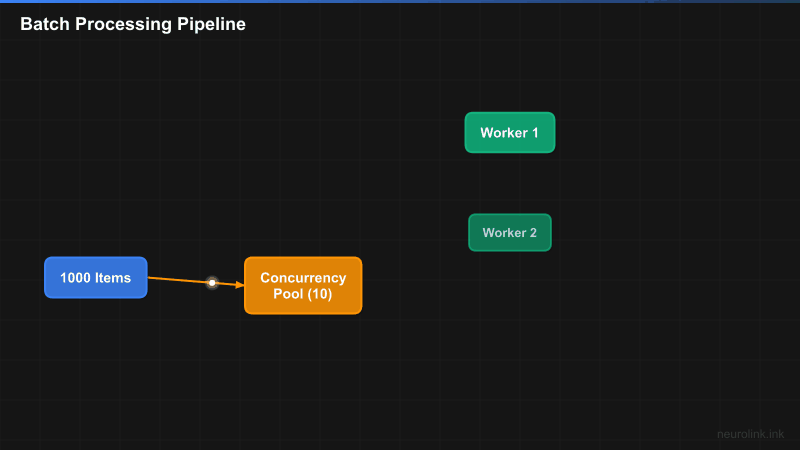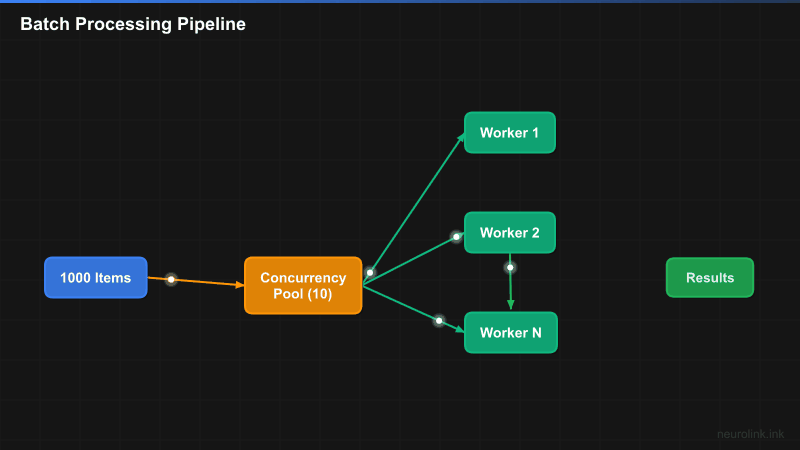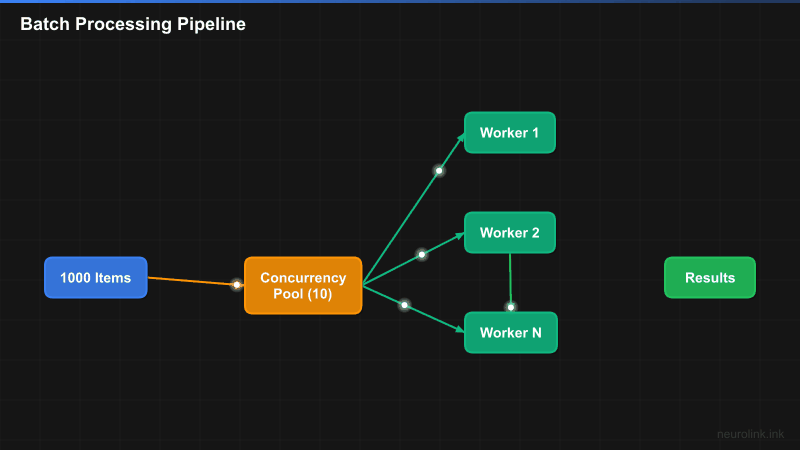
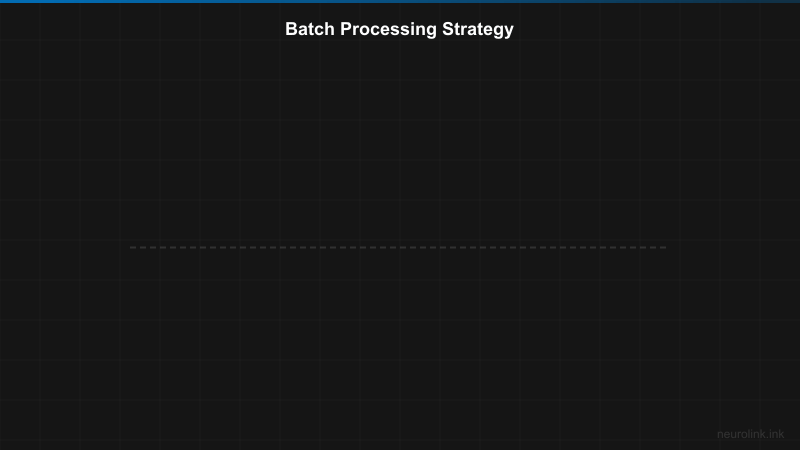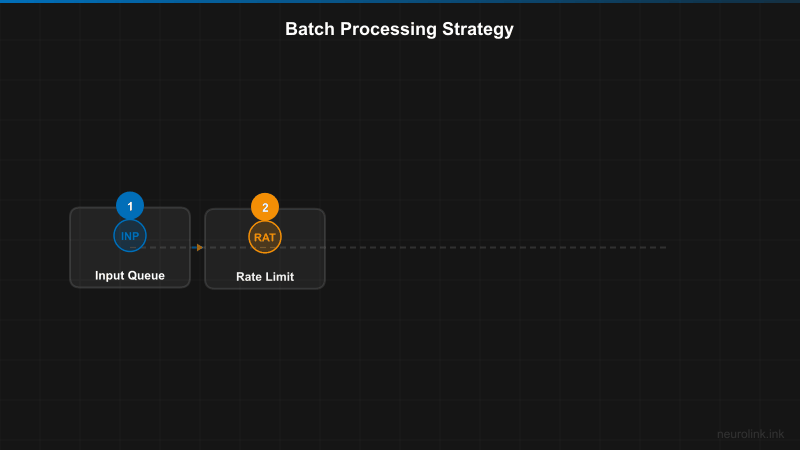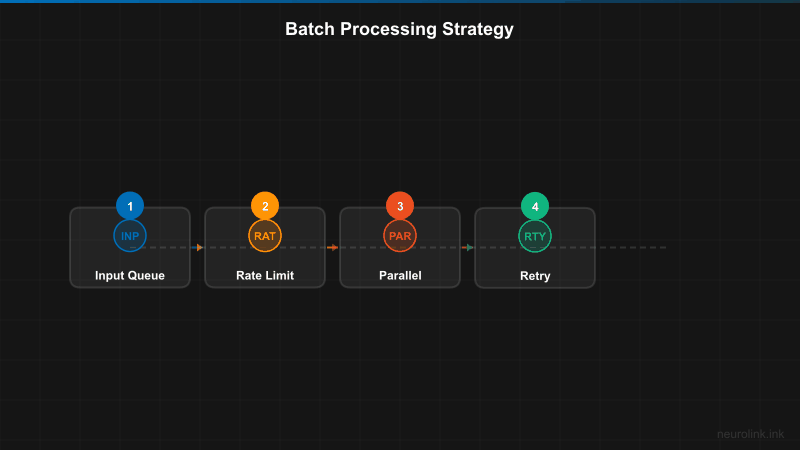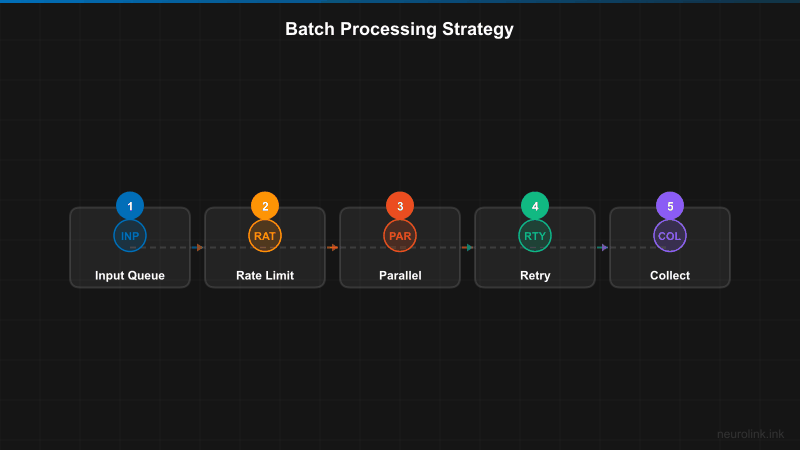
The batch processing pipeline splits input items across a fixed-size concurrency pool, processes them in parallel, and collects results with error isolation:
flowchart TD
A[Input Items\n1...N] --> B[Batch Splitter]
B --> C[Concurrency Pool\nmaxConcurrency: 5]
C --> D1[Worker 1\nneurolink.generate]
C --> D2[Worker 2\nneurolink.generate]
C --> D3[Worker 3\nneurolink.generate]
C --> D4[Worker 4\nneurolink.generate]
C --> D5[Worker 5\nneurolink.generate]
D1 --> E[Results Collector]
D2 --> E
D3 --> E
D4 --> E
D5 --> E
E --> F{All Complete?}
F -->|No| C
F -->|Yes| G[Aggregated Results]
subgraph "Error Handling"
D1 -.->|Error| H[Retry with Backoff]
H -.-> C
end
The key components:
- Concurrency pool:
p-limitcontrols how many requests run simultaneously. NeuroLink’sPerformanceConfig.maxConcurrencydefaults to 5, but this is tunable based on your provider’s rate limits. - Error isolation: Each item is processed independently. A failure on item 47 does not affect items 48 through 1,000.
- Circuit breaker: The circuit breaker pattern prevents cascading failures. After a configurable number of consecutive failures, it stops sending requests to a failing provider.
- Retry handler: Exponential backoff with configurable
maxAttempts,baseDelayMs, andmaxDelayMshandles transient failures.
Basic Batch Pattern
The simplest batch pattern uses p-limit for concurrency control with per-item error isolation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
import { NeuroLink } from '@juspay/neurolink';
import pLimit from "p-limit";
const neurolink = new NeuroLink();
const limit = pLimit(5); // 5 concurrent requests
const items = [
"Summarize this article about climate change...",
"Extract key entities from this legal document...",
"Translate this marketing copy to Spanish...",
// ... hundreds more
];
// Process with controlled concurrency
const results = await Promise.all(
items.map((text, index) =>
limit(async () => {
try {
const result = await neurolink.generate({
input: { text },
provider: "google-ai",
model: "gemini-2.5-flash", // Fast model for batch
temperature: 0.3, // Lower temperature for consistency
maxTokens: 500,
});
return { index, success: true, content: result.content };
} catch (error) {
return { index, success: false, error: (error as Error).message };
}
})
)
);
// Aggregate results
const successful = results.filter((r) => r.success);
const failed = results.filter((r) => !r.success);
console.log(`Completed: ${successful.length}/${results.length}`);
console.log(`Failed: ${failed.length}`);
A few important details:
- Model choice: Use
gemini-2.5-flashorgpt-4o-minifor batch workloads. These models are 5-10x cheaper than their full-size counterparts and fast enough for most extraction and classification tasks. - Temperature: Set
temperatureto 0.1-0.3 for batch processing. You want consistent, reproducible results across items, not creative variation. - maxTokens: Cap the output length to the minimum required. This reduces cost and prevents the occasional item that triggers a lengthy response from slowing down the batch.
- Error wrapping: Each item is wrapped in a try/catch so failures return error objects rather than throwing exceptions that would reject the entire
Promise.all.
Note: The
p-limitlibrary is the same concurrency control mechanism NeuroLink uses internally for operations like concurrent image generation in the PPT module. It is battle-tested and lightweight.
Advanced: Batch with Retry and Progress
Production batch processing needs retry logic for transient failures and progress tracking for monitoring:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
import { NeuroLink } from '@juspay/neurolink';
import pLimit from "p-limit";
const neurolink = new NeuroLink();
interface BatchItem {
id: string;
text: string;
}
interface BatchResult {
id: string;
success: boolean;
content?: string;
attempts: number;
error?: string;
}
async function processBatch(
items: BatchItem[],
options: {
concurrency?: number;
maxRetries?: number;
retryDelayMs?: number;
onProgress?: (completed: number, total: number) => void;
} = {}
): Promise<BatchResult[]> {
const {
concurrency = 5,
maxRetries = 3,
retryDelayMs = 1000,
onProgress,
} = options;
const limit = pLimit(concurrency);
let completed = 0;
const processItem = async (item: BatchItem): Promise<BatchResult> => {
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
const result = await neurolink.generate({
input: { text: item.text },
provider: "google-ai",
model: "gemini-2.5-flash",
timeout: 30000,
});
completed++;
onProgress?.(completed, items.length);
return {
id: item.id,
success: true,
content: result.content,
attempts: attempt,
};
} catch (error) {
if (attempt < maxRetries) {
// Exponential backoff
await new Promise((r) =>
setTimeout(r, retryDelayMs * Math.pow(2, attempt - 1))
);
continue;
}
completed++;
onProgress?.(completed, items.length);
return {
id: item.id,
success: false,
attempts: attempt,
error: (error as Error).message,
};
}
}
// Unreachable but satisfies TypeScript
return { id: item.id, success: false, attempts: maxRetries };
};
return Promise.all(
items.map((item) => limit(() => processItem(item)))
);
}
// Usage
const results = await processBatch(myItems, {
concurrency: 10,
maxRetries: 3,
onProgress: (done, total) => {
console.log(`Progress: ${done}/${total} (${Math.round(done/total*100)}%)`);
},
});
The retry logic uses exponential backoff: the first retry waits 1 second, the second waits 2 seconds, the third waits 4 seconds. This gives the provider time to recover from transient issues like rate limiting or temporary service degradation.
The progress callback lets you build real-time monitoring dashboards, log files, or progress bars. In a web application, you could push progress updates to the client via WebSocket or Server-Sent Events.
Structured Output Batching
When you need consistent, machine-readable output from every batch item, combine batch processing with Zod schemas for structured output:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import { z } from "zod";
const SentimentSchema = z.object({
sentiment: z.enum(["positive", "negative", "neutral"]),
confidence: z.number().min(0).max(1),
keywords: z.array(z.string()),
});
// Batch sentiment analysis with structured output
const reviews = ["Great product!", "Terrible service.", "It was okay."];
const sentiments = await Promise.all(
reviews.map((review) =>
limit(async () => {
const result = await neurolink.generate({
input: { text: `Analyze the sentiment: "${review}"` },
provider: "google-ai",
schema: SentimentSchema,
disableTools: true, // Required for Google with schemas
});
return JSON.parse(result.content);
})
)
);
Structured output ensures every response in your batch follows the same schema. Without it, you might get “The sentiment is positive” from one item and {"sentiment": "positive", "score": 0.95} from another. The Zod schema enforces consistency, and validation catches any malformed responses immediately rather than corrupting downstream data.
Note: When using structured output with Google AI provider, set
disableTools: trueto ensure the schema constraint is applied correctly. This is a provider-specific requirement.
Cost and Performance Optimization
Batch processing cost scales linearly with item count, so model selection has an outsized impact on total spend:
| Model | Speed | Cost per 1K items | Best For |
|---|---|---|---|
| gemini-2.5-flash | Fast | $ | Simple extraction, classification |
| gpt-4o-mini | Fast | $ | General batch processing |
| gemini-2.5-pro | Medium | $$ | Complex analysis |
| gpt-4o | Medium | $$$ | High-quality generation |
| claude-sonnet-4-20250514 | Medium | $$$ | Nuanced content |
Optimization Strategies
Use the cheapest model that meets quality: Run a sample batch (50-100 items) through multiple models. If gemini-2.5-flash produces acceptable results for your use case, there is no reason to pay 10x more for gpt-4o.
Minimize output tokens: Set maxTokens to the minimum needed. A classification task that returns “positive,” “negative,” or “neutral” does not need a 500-token budget.
Enable analytics middleware: Track token usage per batch to identify items that consume disproportionate tokens. These outliers often indicate prompts that need refinement.
Use timeouts: Set timeout on each request to prevent hung connections from blocking a concurrency slot for minutes. A 30-second timeout is generous for most batch tasks.
Tune concurrency by provider: Different providers have different rate limits. OpenAI might tolerate 20 concurrent requests while a Vertex AI endpoint is limited to 5. Start conservative and increase until you see 429 errors, then back off by 20%.
Error Patterns and Resilience
Rate Limiting
When you hit rate limits, the provider returns 429 errors. Reduce concurrency or add delays between requests:
1
2
3
4
5
6
7
// Adaptive concurrency: reduce when hitting rate limits
let currentConcurrency = 10;
function handleRateLimitError() {
currentConcurrency = Math.max(1, Math.floor(currentConcurrency * 0.5));
console.log(`Rate limited. Reducing concurrency to ${currentConcurrency}`);
}
Circuit Breaker
For long-running batches, a circuit breaker prevents wasting time and money on a provider that is down:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// Stop sending requests after N consecutive failures
let consecutiveFailures = 0;
const FAILURE_THRESHOLD = 5;
async function processWithCircuitBreaker(item: BatchItem): Promise<BatchResult> {
if (consecutiveFailures >= FAILURE_THRESHOLD) {
return { id: item.id, success: false, attempts: 0, error: "Circuit breaker open" };
}
try {
const result = await neurolink.generate({
input: { text: item.text },
provider: "google-ai",
model: "gemini-2.5-flash",
});
consecutiveFailures = 0; // Reset on success
return { id: item.id, success: true, content: result.content, attempts: 1 };
} catch (error) {
consecutiveFailures++;
return { id: item.id, success: false, attempts: 1, error: (error as Error).message };
}
}
Dead Letter Queue
Collect failed items for later reprocessing:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
const deadLetterQueue: BatchItem[] = [];
// After batch completes
const failedResults = results.filter(r => !r.success);
const failedItems = failedResults.map(r =>
items.find(item => item.id === r.id)!
);
deadLetterQueue.push(...failedItems);
// Reprocess dead letter queue later (perhaps with different provider)
if (deadLetterQueue.length > 0) {
console.log(`${deadLetterQueue.length} items in dead letter queue for reprocessing`);
const retryResults = await processBatch(deadLetterQueue, {
concurrency: 3, // Lower concurrency for retry
maxRetries: 5, // More retries
});
}
Provider Fallback
NeuroLink’s FallbackConfig enables automatic provider switching when the primary provider fails. For batch workloads, this means a Vertex AI outage automatically reroutes to OpenAI without manual intervention.
What’s Next
You have completed all the steps in this guide. To continue building on what you have learned:
- Review the code examples and adapt them for your specific use case
- Start with the simplest pattern first and add complexity as your requirements grow
- Monitor performance metrics to validate that each change improves your system
- Consult the NeuroLink documentation for advanced configuration options
Related posts: