Building RAG Applications with NeuroLink SDK
Learn how to build RAG applications using NeuroLink SDK for generation and external vector databases for retrieval.

By the end of this guide, you will have a working RAG pipeline that ingests documents, retrieves relevant context via vector search, and generates cited answers through NeuroLink’s unified generate() and stream() interface – with the ability to swap between OpenAI, Anthropic, Vertex, or any other provider for the generation step without changing your retrieval code.
What NeuroLink provides vs external tools
Before diving in, here is what each component provides:
NeuroLink SDK provides:
- Unified LLM generation across 13 providers (OpenAI, Anthropic, Google Vertex, AWS Bedrock, etc.)
- Streaming responses with real-time token delivery
- Multi-provider fallback and retry logic
- MCP tool integration for extended capabilities
- Conversation memory management
External tools required for RAG:
- Embedding generation (OpenAI, Cohere, Voyage AI, or provider-specific APIs)
- Vector databases (Pinecone, Qdrant, Weaviate, Chroma, pgvector, etc.)
- Document processing libraries (pdf-parse, mammoth, etc.)
flowchart TB
subgraph External["External Tools (Not NeuroLink)"]
EmbedAPI[Embedding API<br/>OpenAI/Cohere/Voyage]
VectorDB[(Vector Database<br/>Pinecone/Qdrant/Weaviate)]
DocProcess[Document Processing<br/>pdf-parse/mammoth]
end
subgraph NeuroLink["NeuroLink SDK"]
Generate["generate() Method<br/>LLM Generation"]
Stream["stream() Method<br/>Streaming Responses"]
Providers[13 AI Providers]
end
subgraph RAGApp["Your RAG Application"]
Ingest[Ingestion Pipeline]
Retrieve[Retrieval Logic]
Augment[Context Assembly]
end
DocProcess --> Ingest
EmbedAPI --> Ingest
Ingest --> VectorDB
VectorDB --> Retrieve
Retrieve --> Augment
Augment --> Generate
Generate --> Providers
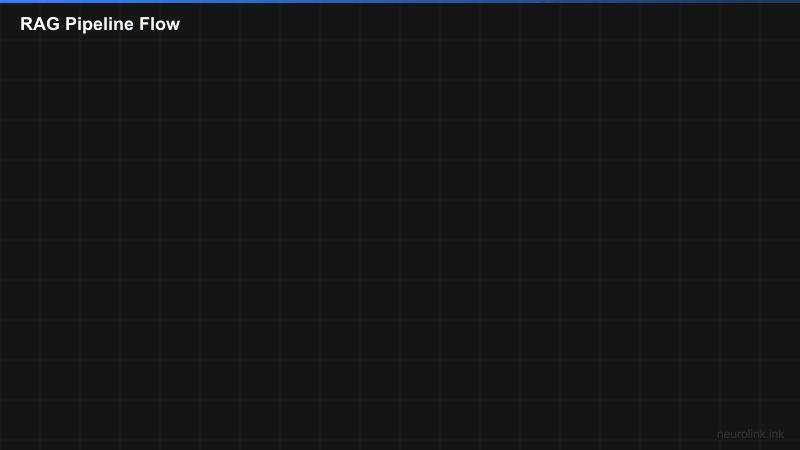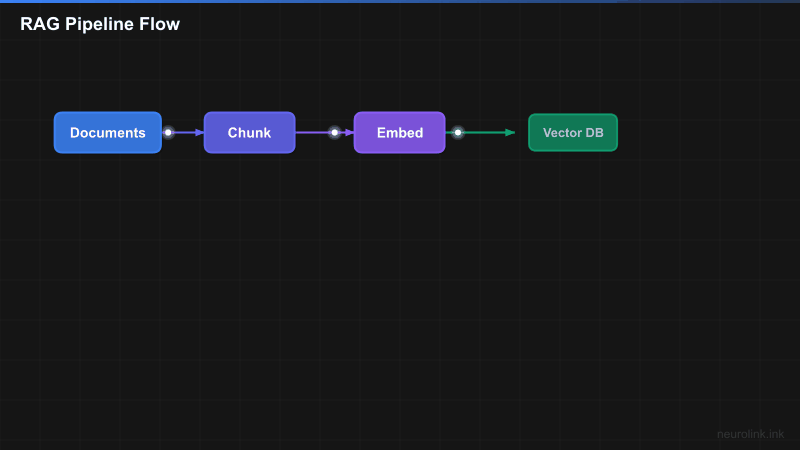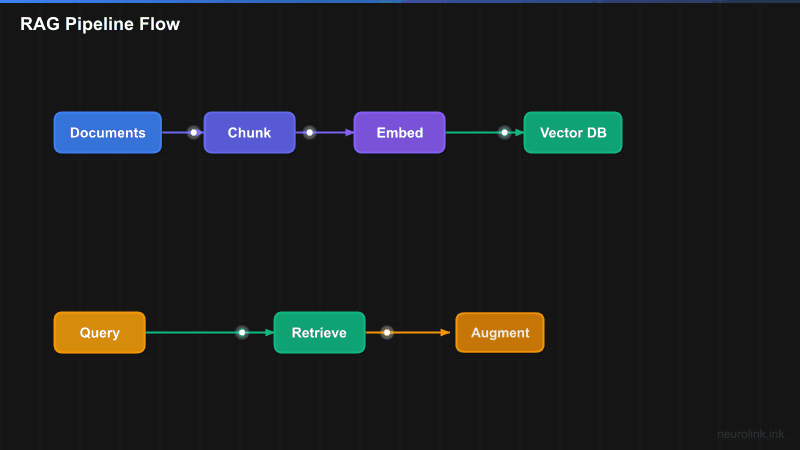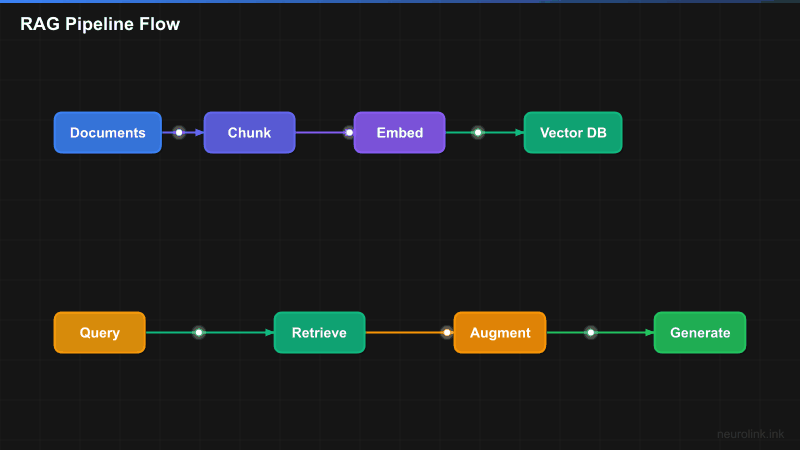
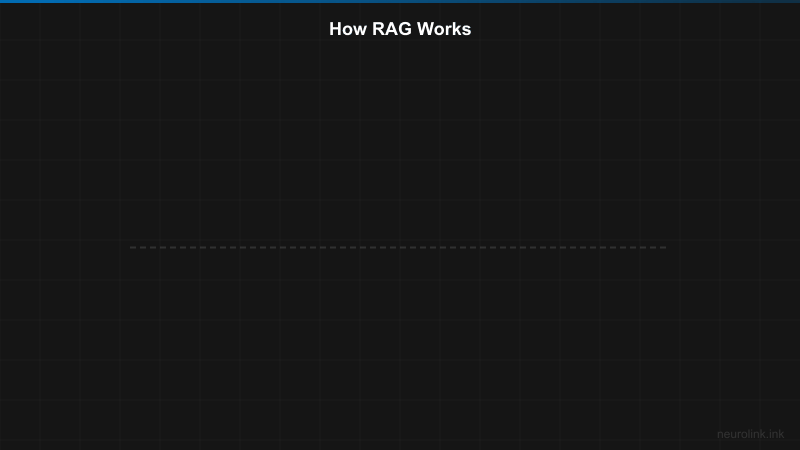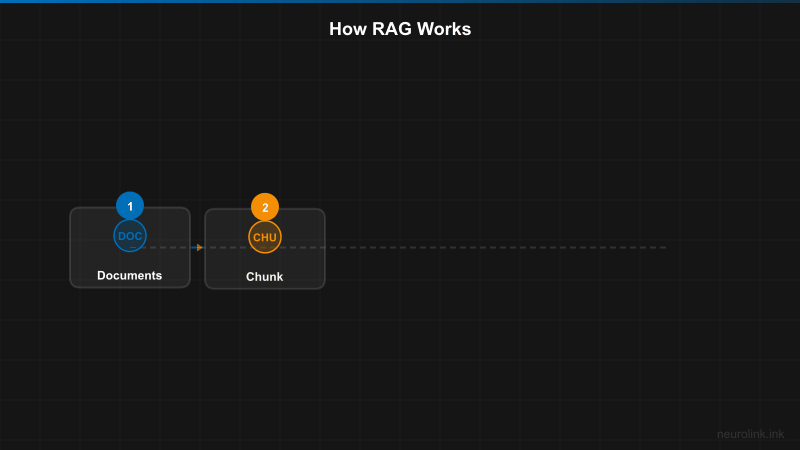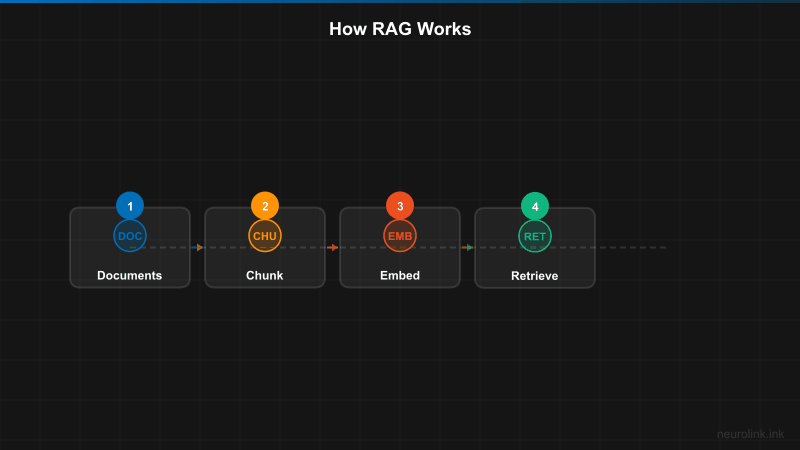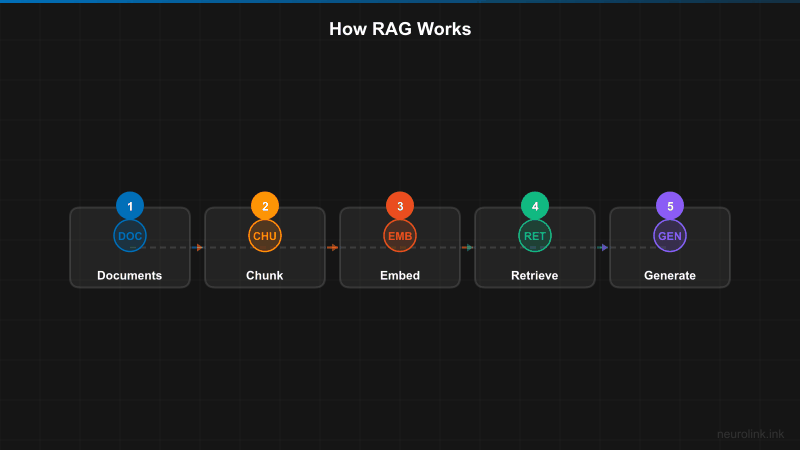
Understanding RAG architecture
A RAG pipeline consists of three main phases:
- Ingestion: Processing documents, generating embeddings, and storing in a vector database
- Retrieval: Finding relevant documents based on user queries
- Generation: Using NeuroLink to synthesize answers from retrieved context
Why RAG over fine-tuning?
| Aspect | RAG | Fine-Tuning |
|---|---|---|
| Update Speed | Instant | Hours to days |
| Cost | Low (storage + retrieval) | High (training compute) |
| Transparency | Source attribution possible | Black box |
| Freshness | Real-time updates | Training cutoff |
| Scale | Unlimited documents | Limited by context |
Setting up your RAG environment
Installation
1
2
3
4
5
6
npm install @juspay/neurolink
# External dependencies for RAG
npm install openai # For embeddings (or use another provider)
npm install @pinecone-database/pinecone # Vector database (or Qdrant, Weaviate, etc.)
npm install pdf-parse mammoth # Document processing
Basic configuration
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import { NeuroLink } from '@juspay/neurolink';
import { OpenAI } from 'openai';
import { Pinecone } from '@pinecone-database/pinecone';
// NeuroLink for LLM generation
const neurolink = new NeuroLink();
// OpenAI for embeddings (external - not part of NeuroLink)
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY
});
// Pinecone for vector storage (external - not part of NeuroLink)
const pinecone = new Pinecone({
apiKey: process.env.PINECONE_API_KEY
});
const index = pinecone.index('knowledge-base');
Document ingestion pipeline
The ingestion pipeline is built entirely with external tools. NeuroLink is not involved until the generation step.
Document processing
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
import * as fs from 'fs/promises';
import * as path from 'path';
import pdfParse from 'pdf-parse';
import mammoth from 'mammoth';
interface ProcessedDocument {
id: string;
content: string;
metadata: {
source: string;
title?: string;
pageCount?: number;
processedAt: Date;
};
}
class DocumentProcessor {
async processFile(filePath: string): Promise<ProcessedDocument> {
const ext = path.extname(filePath).toLowerCase();
const buffer = await fs.readFile(filePath);
let content: string;
let metadata: Record<string, unknown> = {};
switch (ext) {
case '.pdf':
const pdfData = await pdfParse(buffer);
content = pdfData.text;
metadata = { pageCount: pdfData.numpages };
break;
case '.docx':
const docxResult = await mammoth.extractRawText({ buffer });
content = docxResult.value;
break;
case '.txt':
case '.md':
content = buffer.toString('utf-8');
break;
default:
throw new Error(`Unsupported file type: ${ext}`);
}
return {
id: this.generateId(),
content,
metadata: {
source: filePath,
title: path.basename(filePath),
...metadata,
processedAt: new Date()
}
};
}
private generateId(): string {
return `doc_${Date.now()}_${Math.random().toString(36).substr(2, 9)}`;
}
}
Chunking strategies
Proper chunking is critical for RAG performance.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
interface TextChunk {
id: string;
text: string;
documentId: string;
chunkIndex: number;
metadata: Record<string, unknown>;
}
class SemanticChunker {
constructor(
private options: {
targetSize: number; // Target chunk size in characters
overlap: number; // Overlap between chunks
} = { targetSize: 1000, overlap: 100 }
) {}
chunk(doc: ProcessedDocument): TextChunk[] {
const chunks: TextChunk[] = [];
// Split by semantic boundaries (paragraphs, headers)
const sections = this.splitBySemanticBoundaries(doc.content);
let currentChunk = '';
let chunkIndex = 0;
for (const section of sections) {
// If adding this section exceeds target size, save current chunk
if (currentChunk.length + section.length > this.options.targetSize && currentChunk.length > 0) {
chunks.push({
id: `${doc.id}_chunk_${chunkIndex}`,
text: currentChunk.trim(),
documentId: doc.id,
chunkIndex,
metadata: doc.metadata
});
// Start new chunk with overlap from previous
const overlapText = this.getLastNChars(currentChunk, this.options.overlap);
currentChunk = overlapText + section;
chunkIndex++;
} else {
currentChunk += section;
}
}
// Don't forget the last chunk
if (currentChunk.trim().length > 0) {
chunks.push({
id: `${doc.id}_chunk_${chunkIndex}`,
text: currentChunk.trim(),
documentId: doc.id,
chunkIndex,
metadata: doc.metadata
});
}
return chunks;
}
private splitBySemanticBoundaries(content: string): string[] {
// Split by double newlines (paragraphs) and headers
return content
.split(/\n\n+/)
.filter(section => section.trim().length > 0)
.map(section => section + '\n\n');
}
private getLastNChars(text: string, n: number): string {
return text.slice(-n);
}
}
Embedding generation (external service)
Embeddings are generated using external APIs, not NeuroLink.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
class EmbeddingGenerator {
constructor(private openai: OpenAI) {}
async embedChunks(chunks: TextChunk[]): Promise<Array<TextChunk & { embedding: number[] }>> {
const embeddedChunks: Array<TextChunk & { embedding: number[] }> = [];
// Process in batches to avoid rate limits
const batchSize = 20;
for (let i = 0; i < chunks.length; i += batchSize) {
const batch = chunks.slice(i, i + batchSize);
const texts = batch.map(c => c.text);
// Call OpenAI embeddings API (external service)
const response = await this.openai.embeddings.create({
model: 'text-embedding-3-small',
input: texts
});
for (let j = 0; j < batch.length; j++) {
embeddedChunks.push({
...batch[j],
embedding: response.data[j].embedding
});
}
// Rate limiting
if (i + batchSize < chunks.length) {
await this.delay(100);
}
}
return embeddedChunks;
}
async embedQuery(query: string): Promise<number[]> {
const response = await this.openai.embeddings.create({
model: 'text-embedding-3-small',
input: query
});
return response.data[0].embedding;
}
private delay(ms: number): Promise<void> {
return new Promise(resolve => setTimeout(resolve, ms));
}
}
Vector store integration (external service)
Store embeddings in your vector database of choice.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
class VectorStoreManager {
constructor(private index: ReturnType<Pinecone['Index']>) {}
async upsertChunks(chunks: Array<TextChunk & { embedding: number[] }>): Promise<void> {
const vectors = chunks.map(chunk => ({
id: chunk.id,
values: chunk.embedding,
metadata: {
text: chunk.text,
documentId: chunk.documentId,
chunkIndex: chunk.chunkIndex,
source: chunk.metadata.source as string
}
}));
// Upsert in batches
const batchSize = 100;
for (let i = 0; i < vectors.length; i += batchSize) {
const batch = vectors.slice(i, i + batchSize);
await this.index.upsert(batch);
}
}
async query(
embedding: number[],
options: { topK: number; minScore?: number }
): Promise<Array<{ id: string; score: number; metadata: Record<string, unknown> }>> {
const results = await this.index.query({
vector: embedding,
topK: options.topK,
includeMetadata: true
});
return (results.matches || [])
.filter(m => !options.minScore || m.score >= options.minScore)
.map(match => ({
id: match.id,
score: match.score,
metadata: match.metadata || {}
}));
}
async deleteByDocumentId(documentId: string): Promise<void> {
// Note: Pinecone syntax varies by version
await this.index.deleteMany({
filter: { documentId: { $eq: documentId } }
});
}
}
Complete ingestion pipeline
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
class IngestionPipeline {
constructor(
private processor: DocumentProcessor,
private chunker: SemanticChunker,
private embedder: EmbeddingGenerator,
private vectorStore: VectorStoreManager
) {}
async ingest(filePaths: string[]): Promise<{
documentsProcessed: number;
chunksCreated: number;
errors: Array<{ path: string; error: string }>;
}> {
const results = {
documentsProcessed: 0,
chunksCreated: 0,
errors: [] as Array<{ path: string; error: string }>
};
for (const filePath of filePaths) {
try {
// Process document
const doc = await this.processor.processFile(filePath);
// Chunk document
const chunks = this.chunker.chunk(doc);
// Generate embeddings (external API call)
const embeddedChunks = await this.embedder.embedChunks(chunks);
// Store in vector database (external service)
await this.vectorStore.upsertChunks(embeddedChunks);
results.documentsProcessed++;
results.chunksCreated += chunks.length;
console.log(`Ingested ${filePath}: ${chunks.length} chunks`);
} catch (error) {
results.errors.push({
path: filePath,
error: error instanceof Error ? error.message : String(error)
});
}
}
return results;
}
}
Retrieval strategies
Basic vector search
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
interface RetrievedDocument {
id: string;
text: string;
score: number;
metadata: Record<string, unknown>;
}
class VectorRetriever {
constructor(
private embedder: EmbeddingGenerator,
private vectorStore: VectorStoreManager
) {}
async retrieve(query: string, options: {
topK?: number;
minScore?: number;
} = {}): Promise<RetrievedDocument[]> {
const { topK = 5, minScore = 0.7 } = options;
// Generate query embedding (external API call)
const queryEmbedding = await this.embedder.embedQuery(query);
// Search vector database (external service)
const results = await this.vectorStore.query(queryEmbedding, { topK, minScore });
return results.map(r => ({
id: r.id,
text: r.metadata.text as string,
score: r.score,
metadata: r.metadata
}));
}
}
Multi-query retrieval with NeuroLink
Use NeuroLink to generate query variations for better recall.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
class MultiQueryRetriever {
constructor(
private neurolink: NeuroLink,
private baseRetriever: VectorRetriever
) {}
async retrieve(query: string, options: {
numVariations?: number;
topK?: number;
} = {}): Promise<RetrievedDocument[]> {
const { numVariations = 3, topK = 5 } = options;
// Use NeuroLink to generate query variations
const variations = await this.generateQueryVariations(query, numVariations);
// Retrieve for each variation
const allQueries = [query, ...variations];
const allResults = await Promise.all(
allQueries.map(q => this.baseRetriever.retrieve(q, { topK }))
);
// Deduplicate and merge results
return this.mergeAndDeduplicateResults(allResults.flat());
}
private async generateQueryVariations(query: string, count: number): Promise<string[]> {
// Use NeuroLink's generate() method for query expansion
const result = await this.neurolink.generate({
input: {
text: `Generate ${count} alternative phrasings of this search query.
Return only the queries, one per line, without numbering or bullets.
Query: ${query}`
},
provider: 'openai',
model: 'gpt-4-turbo',
temperature: 0.7
});
return result.content
.split('\n')
.map(q => q.trim())
.filter(q => q.length > 0 && q !== query)
.slice(0, count);
}
private mergeAndDeduplicateResults(results: RetrievedDocument[]): RetrievedDocument[] {
const seen = new Map<string, RetrievedDocument>();
for (const doc of results) {
const existing = seen.get(doc.id);
if (!existing || doc.score > existing.score) {
seen.set(doc.id, doc);
}
}
return Array.from(seen.values())
.sort((a, b) => b.score - a.score);
}
}
Contextual compression with NeuroLink
Use NeuroLink to extract only relevant portions from retrieved documents.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class ContextualCompressor {
constructor(private neurolink: NeuroLink) {}
async compress(
query: string,
documents: RetrievedDocument[]
): Promise<RetrievedDocument[]> {
const compressed: RetrievedDocument[] = [];
for (const doc of documents) {
// Use NeuroLink to extract relevant portions
const result = await this.neurolink.generate({
input: {
text: `Extract only the portions of this document that are directly relevant to answering the query. If nothing is relevant, respond with exactly "NOT_RELEVANT".
Query: ${query}
Document:
${doc.text}
Relevant portions:`
},
provider: 'openai',
model: 'gpt-4-turbo',
temperature: 0
});
const compressedText = result.content.trim();
if (compressedText !== 'NOT_RELEVANT') {
compressed.push({
...doc,
text: compressedText
});
}
}
return compressed;
}
}
Generation with NeuroLink
This is where NeuroLink shines. Use its generate() method to synthesize answers from retrieved context.
Context assembly
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
class ContextAssembler {
constructor(
private options: {
maxTokens: number;
format: 'numbered' | 'xml' | 'markdown';
} = { maxTokens: 4000, format: 'xml' }
) {}
assemble(documents: RetrievedDocument[]): string {
let context = '';
let estimatedTokens = 0;
for (let i = 0; i < documents.length; i++) {
const doc = documents[i];
const formatted = this.formatDocument(doc, i + 1);
const docTokens = this.estimateTokens(formatted);
if (estimatedTokens + docTokens > this.options.maxTokens) {
break;
}
context += formatted + '\n\n';
estimatedTokens += docTokens;
}
return context.trim();
}
private formatDocument(doc: RetrievedDocument, index: number): string {
switch (this.options.format) {
case 'numbered':
return `[${index}] (Source: ${doc.metadata.source})\n${doc.text}`;
case 'xml':
return `<document index="${index}" source="${doc.metadata.source}">
${doc.text}
</document>`;
case 'markdown':
return `### Document ${index}\n*Source: ${doc.metadata.source}*\n\n${doc.text}`;
default:
return doc.text;
}
}
private estimateTokens(text: string): number {
// Rough estimation: ~4 characters per token
return Math.ceil(text.length / 4);
}
}
RAG generation with NeuroLink
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
interface RAGResponse {
answer: string;
citations: Array<{
index: number;
source: string;
excerpt: string;
}>;
provider: string;
model: string;
usage?: {
input: number;
output: number;
total: number;
};
}
class RAGGenerator {
constructor(
private neurolink: NeuroLink,
private options: {
provider: string;
model: string;
systemPrompt?: string;
includeCitations: boolean;
temperature?: number;
}
) {}
async generate(
query: string,
context: string,
documents: RetrievedDocument[]
): Promise<RAGResponse> {
const systemPrompt = this.buildSystemPrompt();
const userPrompt = this.buildUserPrompt(query, context);
// Use NeuroLink's generate() method
const result = await this.neurolink.generate({
input: { text: userPrompt },
provider: this.options.provider,
model: this.options.model,
systemPrompt,
temperature: this.options.temperature ?? 0.3
});
return {
answer: result.content,
citations: this.options.includeCitations
? this.extractCitations(result.content, documents)
: [],
provider: result.provider || this.options.provider,
model: result.model || this.options.model,
usage: result.usage ? {
input: result.usage.input,
output: result.usage.output,
total: result.usage.total
} : undefined
};
}
private buildSystemPrompt(): string {
const base = this.options.systemPrompt ||
'You are a helpful assistant that answers questions based on the provided documents.';
if (this.options.includeCitations) {
return `${base}
When answering, cite your sources using [1], [2], etc. notation corresponding to the document numbers provided. Only make claims that are supported by the provided documents. If the documents don't contain enough information to answer the question, say so clearly.`;
}
return base;
}
private buildUserPrompt(query: string, context: string): string {
return `Use the following documents to answer the question.
<documents>
${context}
</documents>
Question: ${query}
Answer:`;
}
private extractCitations(
answer: string,
documents: RetrievedDocument[]
): RAGResponse['citations'] {
const citationPattern = /\[(\d+)\]/g;
const citations: RAGResponse['citations'] = [];
const seen = new Set<number>();
let match;
while ((match = citationPattern.exec(answer)) !== null) {
const index = parseInt(match[1]) - 1;
if (!seen.has(index) && documents[index]) {
seen.add(index);
citations.push({
index: index + 1,
source: documents[index].metadata.source as string,
excerpt: documents[index].text.substring(0, 200) + '...'
});
}
}
return citations;
}
}
Streaming RAG responses
Use NeuroLink’s streaming capability for real-time responses.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
class StreamingRAGGenerator {
constructor(
private neurolink: NeuroLink,
private options: {
provider: string;
model: string;
systemPrompt?: string;
}
) {}
async *generateStream(
query: string,
context: string
): AsyncGenerator<{ type: 'content' | 'complete'; content: string }> {
const systemPrompt = this.options.systemPrompt ||
'You are a helpful assistant that answers questions based on the provided documents. Cite sources using [1], [2], etc. notation.';
const userPrompt = `Use the following documents to answer the question.
<documents>
${context}
</documents>
Question: ${query}
Answer:`;
// Use NeuroLink's stream() method
const result = await this.neurolink.stream({
input: { text: userPrompt },
provider: this.options.provider,
model: this.options.model,
systemPrompt
});
let fullContent = '';
for await (const chunk of result.stream) {
if (chunk.content) {
fullContent += chunk.content;
yield {
type: 'content',
content: chunk.content
};
}
}
yield {
type: 'complete',
content: fullContent
};
}
}
Complete RAG application
Bringing everything together into a production-ready application.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
class RAGApplication {
private ingestionPipeline: IngestionPipeline;
private retriever: VectorRetriever;
private multiQueryRetriever: MultiQueryRetriever;
private contextAssembler: ContextAssembler;
private generator: RAGGenerator;
constructor(config: {
neurolink: NeuroLink;
openai: OpenAI;
pineconeIndex: ReturnType<Pinecone['Index']>;
generationModel?: string;
generationProvider?: string;
}) {
// External services
const embedder = new EmbeddingGenerator(config.openai);
const vectorStore = new VectorStoreManager(config.pineconeIndex);
// Ingestion (uses external services only)
this.ingestionPipeline = new IngestionPipeline(
new DocumentProcessor(),
new SemanticChunker({ targetSize: 1000, overlap: 100 }),
embedder,
vectorStore
);
// Retrieval (uses external services)
this.retriever = new VectorRetriever(embedder, vectorStore);
// Multi-query retrieval (uses NeuroLink for query expansion)
this.multiQueryRetriever = new MultiQueryRetriever(
config.neurolink,
this.retriever
);
// Context assembly
this.contextAssembler = new ContextAssembler({
maxTokens: 4000,
format: 'xml'
});
// Generation (uses NeuroLink)
this.generator = new RAGGenerator(config.neurolink, {
provider: config.generationProvider || 'openai',
model: config.generationModel || 'gpt-4-turbo',
includeCitations: true,
temperature: 0.3
});
}
async ingestDocuments(filePaths: string[]): Promise<{
documentsProcessed: number;
chunksCreated: number;
errors: Array<{ path: string; error: string }>;
}> {
return this.ingestionPipeline.ingest(filePaths);
}
async query(question: string, options: {
useMultiQuery?: boolean;
topK?: number;
} = {}): Promise<RAGResponse & {
retrievedDocuments: RetrievedDocument[];
latencyMs: number;
}> {
const startTime = Date.now();
const { useMultiQuery = true, topK = 5 } = options;
// Step 1: Retrieve relevant documents
const retrieved = useMultiQuery
? await this.multiQueryRetriever.retrieve(question, { topK })
: await this.retriever.retrieve(question, { topK });
// Step 2: Assemble context
const context = this.contextAssembler.assemble(retrieved);
// Step 3: Generate answer using NeuroLink
const response = await this.generator.generate(question, context, retrieved);
return {
...response,
retrievedDocuments: retrieved,
latencyMs: Date.now() - startTime
};
}
}
Usage example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import { NeuroLink } from '@juspay/neurolink';
import { OpenAI } from 'openai';
import { Pinecone } from '@pinecone-database/pinecone';
async function main() {
// Initialize services
const neurolink = new NeuroLink();
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const pinecone = new Pinecone({ apiKey: process.env.PINECONE_API_KEY });
// Create RAG application
const rag = new RAGApplication({
neurolink,
openai,
pineconeIndex: pinecone.index('knowledge-base'),
generationProvider: 'openai',
generationModel: 'gpt-4-turbo'
});
// Ingest documents
const ingestionResult = await rag.ingestDocuments([
'./docs/user-guide.pdf',
'./docs/api-reference.md',
'./docs/faq.txt'
]);
console.log(`Ingested ${ingestionResult.documentsProcessed} documents`);
// Query the knowledge base
const response = await rag.query('How do I configure authentication?');
console.log('Answer:', response.answer);
console.log('Citations:', response.citations);
console.log('Latency:', response.latencyMs, 'ms');
}
main().catch(console.error);
Using different providers with NeuroLink
One of NeuroLink’s strengths is provider flexibility. Use different providers for generation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// Use Anthropic Claude for generation
const claudeRAG = new RAGApplication({
neurolink,
openai, // Still use OpenAI for embeddings
pineconeIndex,
generationProvider: 'anthropic',
generationModel: 'claude-3-5-sonnet-20241022'
});
// Use Google Vertex AI for generation
const vertexRAG = new RAGApplication({
neurolink,
openai,
pineconeIndex,
generationProvider: 'vertex',
generationModel: 'gemini-3-flash'
});
// Use AWS Bedrock for generation
const bedrockRAG = new RAGApplication({
neurolink,
openai,
pineconeIndex,
generationProvider: 'bedrock',
generationModel: 'anthropic.claude-3-sonnet-20240229-v1:0'
});
Note: Model names and IDs in code examples reflect versions available at time of writing. Model availability, naming conventions, and pricing change frequently. Always verify current model IDs with your provider’s documentation before deploying to production.
Alternative vector databases
The examples use Pinecone, but you can easily swap in other vector databases.
Qdrant example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import { QdrantClient } from '@qdrant/js-client-rest';
class QdrantVectorStore {
constructor(
private client: QdrantClient,
private collectionName: string
) {}
async upsert(chunks: Array<TextChunk & { embedding: number[] }>): Promise<void> {
await this.client.upsert(this.collectionName, {
points: chunks.map((chunk, i) => ({
id: i,
vector: chunk.embedding,
payload: {
id: chunk.id,
text: chunk.text,
documentId: chunk.documentId,
source: chunk.metadata.source
}
}))
});
}
async query(embedding: number[], topK: number) {
const results = await this.client.search(this.collectionName, {
vector: embedding,
limit: topK,
with_payload: true
});
return results.map(r => ({
id: r.payload?.id as string,
score: r.score,
metadata: r.payload || {}
}));
}
}
Weaviate example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import weaviate from 'weaviate-ts-client';
class WeaviateVectorStore {
constructor(
private client: ReturnType<typeof weaviate.client>,
private className: string
) {}
async upsert(chunks: Array<TextChunk & { embedding: number[] }>): Promise<void> {
const batch = this.client.batch.objectsBatcher();
for (const chunk of chunks) {
batch.withObject({
class: this.className,
vector: chunk.embedding,
properties: {
chunkId: chunk.id,
text: chunk.text,
documentId: chunk.documentId,
source: chunk.metadata.source
}
});
}
await batch.do();
}
async query(embedding: number[], topK: number) {
const result = await this.client.graphql
.get()
.withClassName(this.className)
.withNearVector({ vector: embedding })
.withLimit(topK)
.withFields('chunkId text documentId source _additional { certainty }')
.do();
return result.data.Get[this.className].map((r: Record<string, unknown>) => ({
id: r.chunkId as string,
score: (r._additional as Record<string, number>).certainty,
metadata: { text: r.text, source: r.source }
}));
}
}
Production considerations
Error handling
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class ResilientRAGApplication {
constructor(private rag: RAGApplication) {}
async query(question: string, options: {
maxRetries?: number;
fallbackProviders?: string[];
} = {}): Promise<RAGResponse> {
const { maxRetries = 3, fallbackProviders = ['openai', 'anthropic', 'vertex'] } = options;
let lastError: Error | undefined;
for (let attempt = 0; attempt < maxRetries; attempt++) {
for (const provider of fallbackProviders) {
try {
return await this.rag.query(question, { useMultiQuery: true });
} catch (error) {
lastError = error instanceof Error ? error : new Error(String(error));
console.warn(`Attempt ${attempt + 1} with ${provider} failed:`, lastError.message);
}
}
}
throw new Error(`All RAG attempts failed. Last error: ${lastError?.message}`);
}
}
Caching
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import { LRUCache } from 'lru-cache';
class CachedRAGApplication {
private cache: LRUCache<string, RAGResponse>;
constructor(
private rag: RAGApplication,
options: { maxSize?: number; ttlMs?: number } = {}
) {
this.cache = new LRUCache({
max: options.maxSize || 1000,
ttl: options.ttlMs || 3600000 // 1 hour default
});
}
async query(question: string): Promise<RAGResponse & { cached: boolean }> {
const cacheKey = this.hashQuery(question);
const cached = this.cache.get(cacheKey);
if (cached) {
return { ...cached, cached: true };
}
const response = await this.rag.query(question);
this.cache.set(cacheKey, response);
return { ...response, cached: false };
}
private hashQuery(query: string): string {
return query.toLowerCase().trim().replace(/\s+/g, ' ');
}
}
Summary
This guide covers a complete working RAG pipeline: document processing, semantic chunking, embedding generation, vector storage, multi-query retrieval, contextual compression, and generation with citations. The architecture is:
- External tools for ingestion and retrieval – document processing libraries, embedding APIs (OpenAI, Cohere), and vector databases (Pinecone, Qdrant, Weaviate)
- NeuroLink for generation –
generate()orstream()to synthesize answers from retrieved context - NeuroLink for query enhancement – generate query variations and compress retrieved context
NeuroLink does not provide built-in embedding generation or vector storage. It excels at the generation step, where its unified multi-provider interface and provider fallback make your RAG pipeline resilient.
Resources
- NeuroLink SDK Documentation
- OpenAI Embeddings API
- Pinecone Documentation
- Qdrant Documentation
- Weaviate Documentation
Related posts: